深入理解JVM(二)——类文件结构
“Class 文件”并非特指某个存在于具体磁盘中的问题,而应当是一串二进制字节流,无论其以何种形式存在,包括但不限于磁盘文件、网络、数据库、内存或者动态产生等。
Java 能够实现”一次编译,到处运行”,这其中 class 文件要占大部分功劳。为了让 Java 语言具有良好的跨平台能力,Java 独具匠心的提供了一种可以在所有平台上都能使用的一种中间代码——字节码类文件(.class文件)。有了字节码,无论是哪种平台(如:Mac、Windows、Linux 等),只要安装了虚拟机都可以直接运行字节码。
有了字节码,也解除了 Java 虚拟机和 Java 语言之间的耦合。Java虚拟机并不一定只能运行Java语言编写的程序,而是只认Class文件,其他语言如Kotlin、Groovy、Scala等都可以只需要编译成符合《Java虚拟机规范》的Class文件都可以运行在Java虚拟机中。如下图所示:
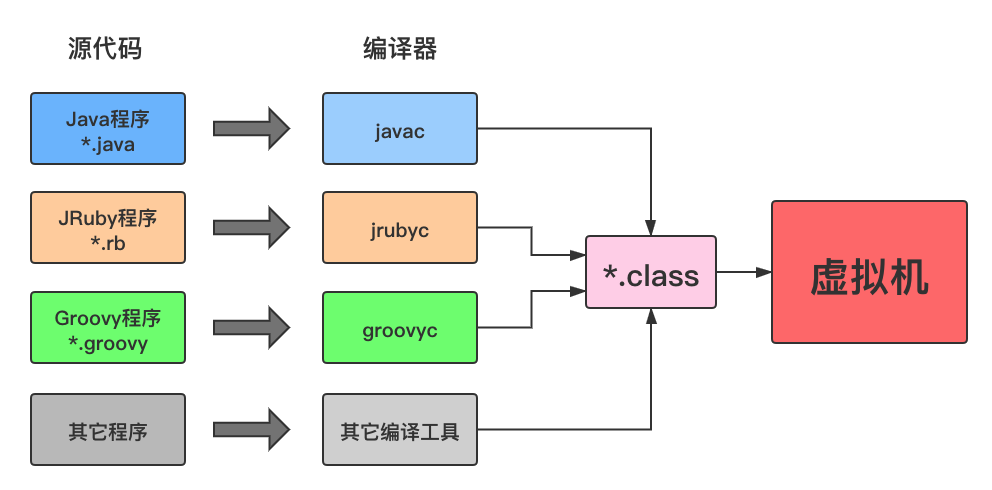
Class文件结构
Class文件是一组以 8 个字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在文件之中,中间没有添加任何分隔符,这使得整个Class文件中存储的内容几乎全部是程运行的必要数据,没有空隙存在。当遇到需要占用 8 个字节以上空间的数据项时,则会按照高位在前(Big-Endian,大端)的方式分割成若干个 8 个字节进行存储。结构如下图所示。

根据《Java虚拟机规范》的规定,Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表。
- 无符号数属于基本的数据类型,以 u1、u2、u4、u8 来分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成的字符值。
- 表示由多个无符号数或者其他表作为数据项构成的复合数据类型,为了便于区分,所有表的命名都习惯性地以”_info“结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上也可以视作是一张表,这张表由下表所示的数据项按严格顺序排列构成。
| 类 型 | 字 段 名 | 数 量 | 名 称 |
|---|---|---|---|
| u4 | magic | 1 | 魔数 |
| u2 | minor_version | 1 | 主版本号 |
| u2 | major_version | 1 | 副版本号 |
| u2 | constant_pool_count | 1 | 常量池大小 |
| cp_info | constant_pool | constant_pool_count-1 | 常量池 |
| u2 | access_flags | 1 | 访问标志 |
| u2 | this_class | 1 | 当前类索引 |
| u2 | super_class | 1 | 父类索引 |
| u2 | interfaces_count | 1 | 接口索引集合大小 |
| u2 | interfaces | interfaces_count | 接口索引集合 |
| u2 | fields_count | 1 | 字段索引集合大小 |
| field_info | fields | fields_count | 字段索引集合 |
| u2 | methods_count | 1 | 方法索引集合大小 |
| method_info | methods | methods_count | 方法索引集合 |
| u2 | attributes_count | 1 | 属性索引集合大小 |
| attribute_info | attributes | attribute_count | 属性索引集合 |
无符号数和表的关系可以用下图表示:
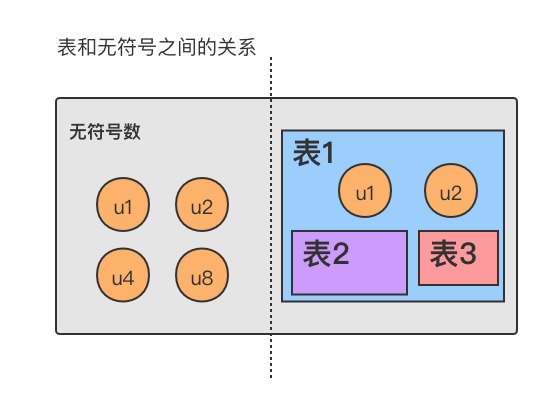
可以看出,在一张表中可以包含其他无符号数和其他表格。伪代码可以如下所示:
1 | |
接下来,我们通过编写一个例子来看看这个表中各个数据项的具体含义:
1 | |
我们通过 javac 编译下列代码生成 Test.class 字节码文件,然后使用 16 进制编辑器打开 class 文件查看内容:

上图中都是一些 16 进制数字,每两个字符代表一个字节。
魔数与Class文件的版本
每个Class文件的头 4 个字节被称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的 Class 文件。魔数被用作格式标准校验是很常见的行为,Class 文件中的魔数值为 0xCAFEBABE ,跟 Java 的”咖啡豆“含义相互呼应。

紧接着魔数的 4 个字节存储的是 Class 文件的版本号:第 5 和第 6 个字节(0000)是次版本号,第 7 和第 8 个字节(0034)是主版本号。0034 对应的十进制是 52,也就是 jdk1.8.0 。

常量池
紧跟在版本号之后的是一个叫作常量池的表(cp_info)。在常量池中保存了类的各种相关信息,比如类的名称、父类的名称、类中的方法名、参数名称、参数类型等,这些信息都是以各种表的形式保存在常量池中的。
由于常量池中常量的数量是不固定的,所以在常量池的入口需要放置一项u2类型的数据,代表常量池容量计数值(constant_pool_count)。例如本例中常量池大小为 0x001D ,即 29 ,表示常量池中有 28 项常量,索引值范围为 1~28 。这里将 0 空出来是为了后面有表的索引值为 0 时,可以表达“不引用任何一个常量池项目”的含义。

常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。字面量比较接近于 Java 语言层面的常量概念,如文本字符串、被声明为 final 的常量值等。而符号引用则属于编译原理方面的概念,主要包括下面几类常量:
- 被模块导出或者开放的包(Package)
- 类和接口的全限定名(Fully Qualified Name)
- 字段的名称和描述符(Descriptor)
- 方法的名称和描述符
- 方法句柄和方法类型(Method Handle、Method Type、Invoke Dynamic)
- 动态调用点和动态常量(Dynamically-Computed Call Site、Dynamically-Computed Constant)
常量池中的每一项都是一个表,截止至 JDK13 ,常量表中分别有17种不同的项目类型。
| 类 型 | 标 志 | 描 述 |
|---|---|---|
| CONSTANT_Utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整形字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长精度型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的部分符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MethodType_info | 16 | 表示方法类型 |
| CONSTANT_Dynamic_info | 17 | 表示一个动态计算常量 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
| CONSTANT_Module_info | 19 | 表示一个模块 |
| CONSTANT_Package_info | 20 | 表示一个模块中开放或者导出的包 |
这 17 类表都有一个共同的特点,表结构起始的第一位是个 u1 类型的标志位,即上表中的标志,代表着当前常量属于哪种常量类型。下面以CONSTANT_Class_info 和 CONSTANT_Utf8_info 这两张表为例,来分析一下表结构。
首先,CONSTANT_Class_info 表具体结构如下所示:
1 | |
- tab:上面说过了是表示表的类型,例如7表示CONSTANT_Class_info类型表,占用一个字节大小。
- name_index:是一个索引值,可以将它理解为一个指针,指向常量池中索引为name_index的常量表。比如name_index = 2,则它指向常量池中第2个常量。
接下来再看CONSTANT_Utf8_info表具体结构如下:
1 | |
解释说明:
- tag:值为1,表示是CONSTANT_Utf8_info类型表。
- length:length表示u1[]的长度,比如length=5,则表示接下来的数据是 5 个连续的u1类型数据。
- bytes:u1类型数组,长度为上面第2个参数length的值。
而我们在java代码中声明的String字符串最终在class文件中的存储格式就是CONSTANT_utf8_info。因此一个字符串最大长度也就是u2所能代表的最大值65536个,但是需要使用2个字节来保存null值,因此一个字符串的最大长度为 65536 - 2 = 65534。
不难看出,在常量池内部的表中也有相互之间的引用。用一张图来理解CONSTANT_Class_info和CONSTANT_utf8_info表格之间的关系,如下图所示:
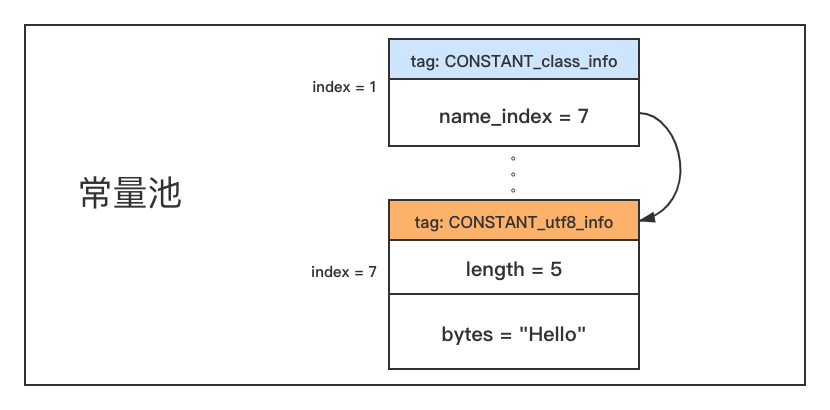
接下来我们继续基于上面的例子分析。上面说到版本号之后就是常量池大小,为0x001D即29,表示常量计数器为28。紧接着就是第一个常量,如下所示:

第一个字节表示tag,0x0a转化为十进制后为10,通过上面的表格我们知道tag=10时的表类型为CONSTANT_Methodref_info,因此第一个常量表结构为方法引用表。其结构如下:
1 | |
在“0a”之后的2个字节指向这个方法是属于哪个类,紧接的2个字节指向这个方法的名称和类型。它们的值分别是:
- 0006:十进制6,表示指向常量池中的第6个常量。
- 0015:十进制21,表示指向常量池中的第21个常量。
由于每个常量表占用字节的长度是不一定的,所以我们必须顺序解析到第6个常量才能知道第6个常量是什么类型,不过这里我们可以利用javap命令来帮助我们查看常量池的内容:
1 | |
命令执行后结果如下:
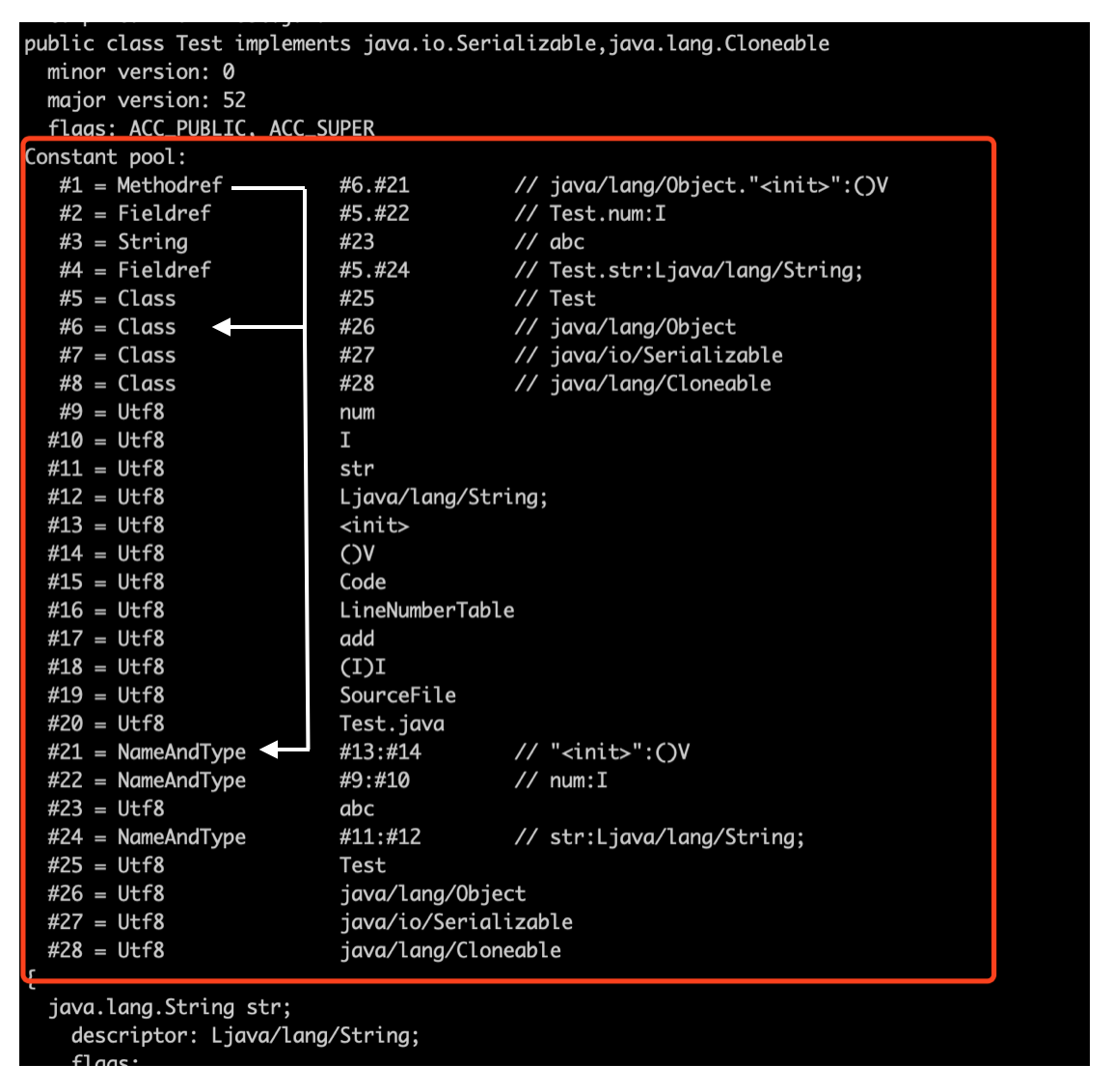
正如我们刚才分析的一样,常量池中第一个常量是Methodref类型,指向下标6和下标21的常量。其中下标21的常量类型为NameAndType,它对应的数据结构如下:
1 | |
而下标在21的NameAndType的name_index和type_index分别指向了13和14,也就是“
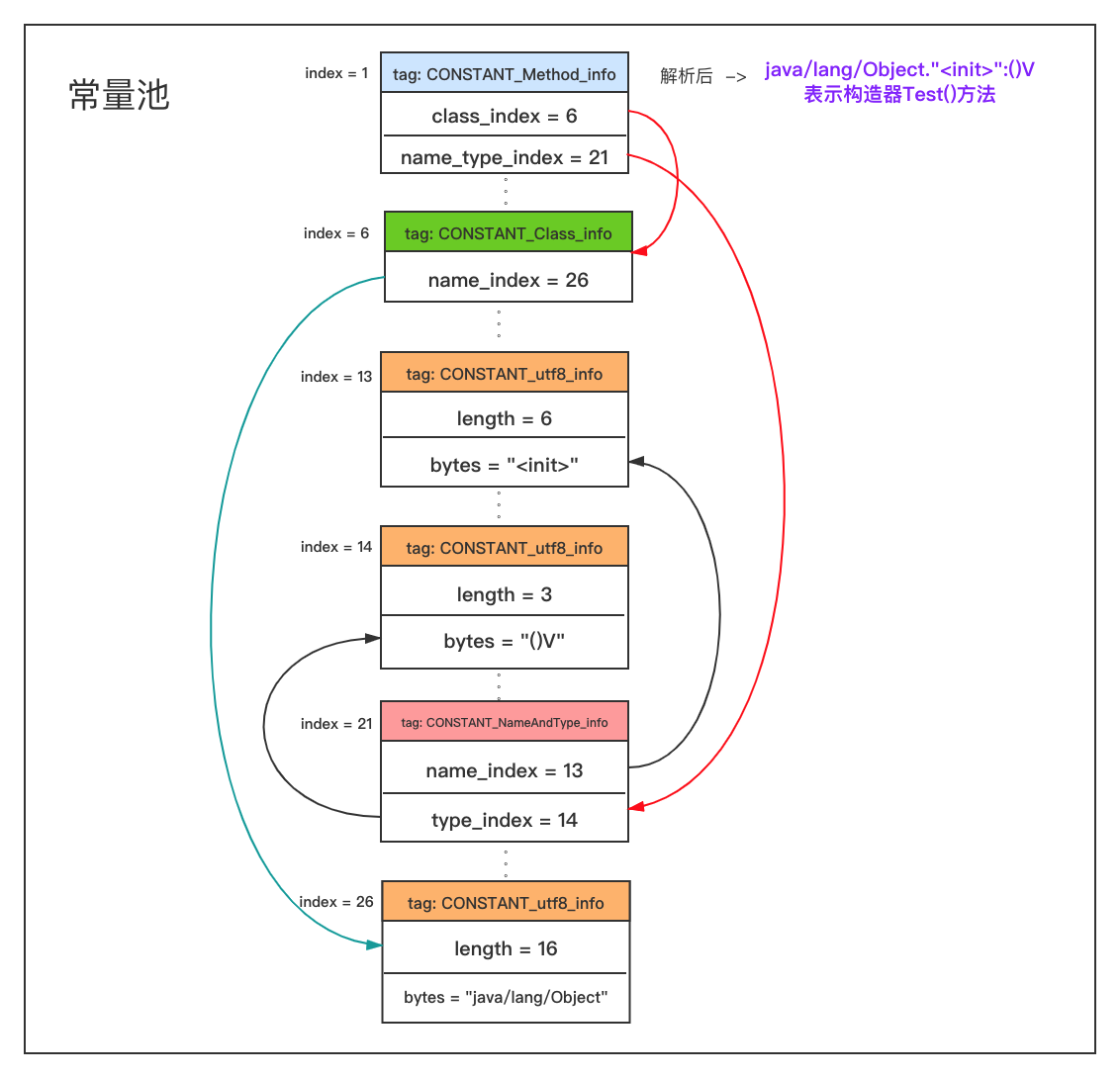
仔细解析层层引用,最后我们可以看出,Test.class文件中常量池的第1个常量保存的是Object中的默认构造器方法。
访问标志
在常量池结束之后,紧接着的2个字节代表访问标志(access_flags),如下图所示:
这个标志用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等等。具体的标志位以及标志的含义见下表:
| 标 志 名 称 | 标 志 值 | 含 义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 是否为public类型 |
| ACC_FINAL | 0x0010 | 是否被声明为final,只有类可设置 |
| ACC_SUPER | 0x0020 | 是否允许使用invokespecial字节码指令的新语义,JDK 1.0.2 之后默认为真 |
| ACC_INTERFACE | 0x0200 | 标识这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 是否为abstract类型,对于接口或抽象类来说为真 |
| ACC_SYNTHETIC | 0x1000 | 标识这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x2000 | 标识这是一个注解 |
| ACC_ENUM | 0x4000 | 标识这是一个枚举 |
| ACC_MODULE | 0x8000 | 标识这是一个模块 |
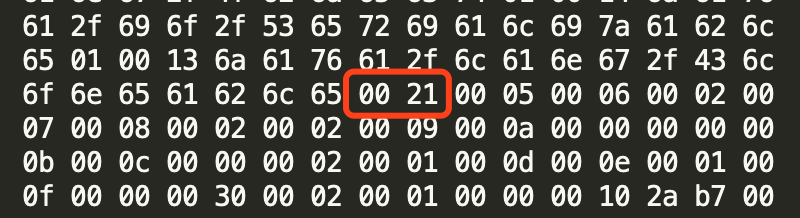
我们定义的Test.java是一个普通Java类,不是接口、枚举或注解。并且被public修饰但没有被声明为final和abstract,并且它使用了JDK 1.2之后的编译器进行编译,因此它所对应的access_flags为0021(0X0001和0X0020相结合)。
类索引、父类索引与接口索引集合
在访问标志后的 2 个字节就是类索引(this_class),类索引后的 2 个字节就是父类索引(super_class),父类索引后的 2 个字节则是接口索引计数器(interfaces)。类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了java.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不为0。接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements关键字(如果这个Class文件表示的是一个接口,则应当是extends关键字)后的接口顺序从左到右排列在接口索引集合中。
在我们的例子中如下图所示:
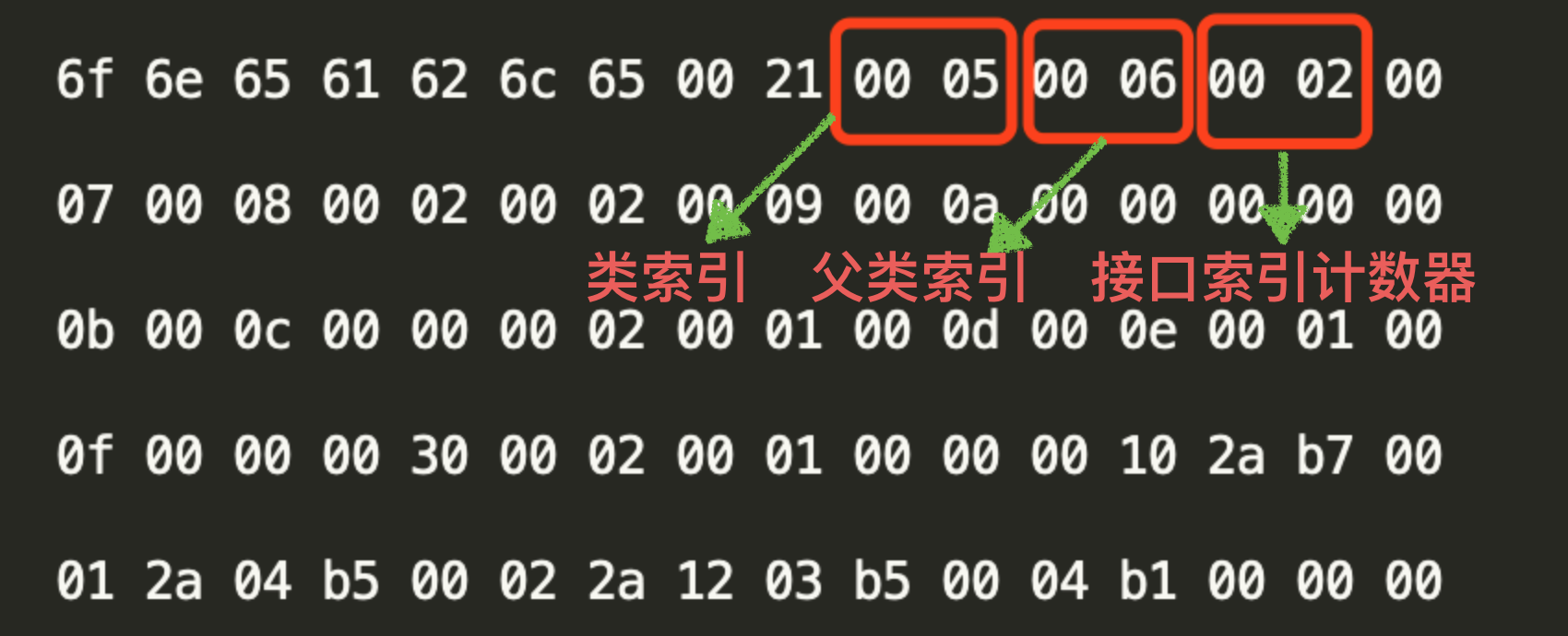
可以看出类索引指向常量池中的第 5 个常量,父类索引指向常量池中的第 6 个常量,并且实现的接口个数为 2 个。再回顾下常量池中的数据:

从图中可以看出,第 5 个常量和第 6 个常量均为 CONSTANT_Class_info 表类型,并且代表的类分别是“Test”和“Object”。再看接口计数器,因为接口计数器的值是 2,代表这个类实现了 2 个接口。查看在接口计数器之后的 4 个字节分别为:
- 0007:指向常量池中的第7个常量,从图中可以看出第7个常量值为“Serializable”。
- 0008:指向常量池中的第8个常量,从图中可以看出第8个常量值为“Cloneable”。
综上所述,可以得出如下结论:当前类为 Test 继承自 Object 类,并实现了“Serializable”和“Cloneable”这两个接口。
字段表集合
紧跟在接口索引集合后面的就是字段表(field_info)了,字段表用于描述接口或者类中声明的变量。Java语言中的“字段”(Field)包括类级变量以及实例级变量,但不包括在方法内部声明的局部变量。
同样, 一个类中的变量个数是不固定的,因此在字段表集合之前还是使用一个计数器来表示变量的个数,如下所示:

0002 表示类中声明了 2 个变量(在 class 文件中叫字段),字段计数器之后会紧跟着 2 个字段表的数据结构。
字段表的具体结构如下:
1 | |
字段访问标志放在access_flags项目中,它与类中的access_flags项目是非常类似的,都是一个u2的数据类型,其中可以设置的标志位和含义如下表所示。
| 标 志 名 称 | 标 志 值 | 含 义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 字段是否为public |
| ACC_PRIVATE | 0x0002 | 字段是否为private |
| ACC_PROTECTED | 0x0004 | 字段是否为protected |
| ACC_STATIC | 0x0008 | 字段是否static |
| ACC_FINAL | 0x0010 | 字段是否final |
| ACC_VOLATILE | 0x0040 | 字段是否volatile |
| ACC_TRANSIENT | 0x0080 | 字段是否transient |
| ACC_SYNTHETIC | 0x1000 | 字段是否synthetic |
| ACC_ENUM | 0x4000 | 字段是否为enum |
很明显,由于语法规则的约束,ACC_PUBLIC、ACC_PRIVATE、ACC_PROTECTED三个标志最 多只能选择其一,ACC_FINAL、ACC_VOLATILE不能同时选择。接口之中的字段必须有 ACC_PUBLIC、ACC_STATIC、ACC_FINAL标志,这些都是由Java本身的语言规则所导致的。
跟随access_flags标志的是两项索引值:name_index和descriptor_index。它们都是对常量池项的引用,分别代表着字段的简单名称以及字段和方法的描述符。
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,如下表所示。
| 标 识 字 符 | 含 义 |
|---|---|
| B | 基本类型byte |
| C | 基本类型char |
| D | 基本类型double |
| F | 基本类型float |
| I | 基本类型int |
| J | 基本类型long |
| S | 基本类型short |
| Z | 基本类型boolean |
| V | 特殊类型void |
| L | 对象类型,如Ljava/lang/Object; |
对于数组类型,每一维度将使用一个前置的“ [”字符来描述,如一个定义为“ jav-a.lang.String[][]”类型的二维数组将被记录成“ [[Ljava/lang/String;”,一个整型数组“ int []”将被记录成“ [I”。
描述符来描述方法时,按照先参数列表、后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法void inc()的描述符为“()V”,方法java.lang.String toString()的描述符为“()Ljava/lang/String;”,方法int indexOf(char[]so-urce,int sourceOffset,int sourceCount,char[] target,int targetOffset,int targetCount,int fromIndex)的描述符为“([CII[CIII)I”。
继续解析 Text.class 中的字段表,其结构如下图所示:
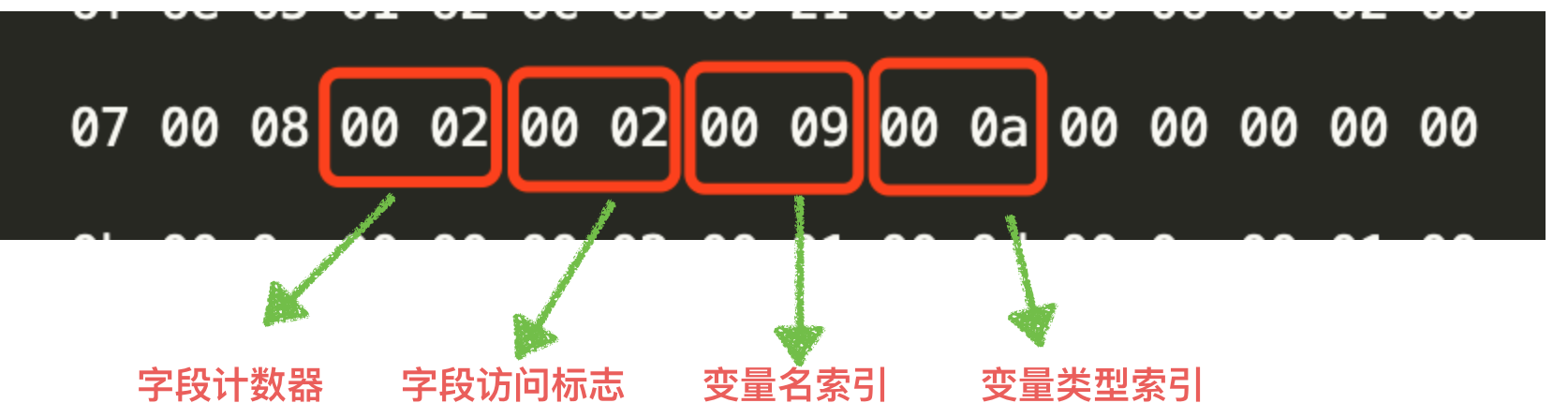
图中的访问标志的值为 0002,代表它是 private 类型。变量名索引指向常量池中的第 9 个常量,变量名类型索引指向常量池中第 10 个常量。第 9 和第 10 个常量分别为“num”和“I”,如下所示:
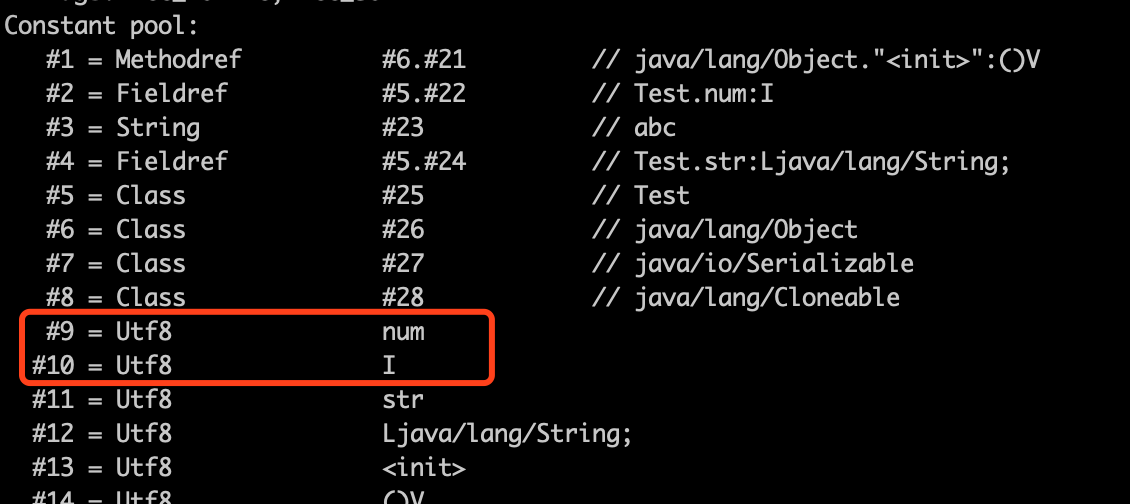
因此可以得知类中有一个名为 num,类型为 int 类型的变量。对于第 2 个变量的解析过程也是一样,就不再过多介绍。
注意事项:
字段表集合中不会列出从父类或者父接口中继承而来的字段。
内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
方法表集合
Class文件存储格式中对方法的描述与对字段的描述采用了几乎完全一致的方式,方法表的结构如同字段表一样,依次包括访问标志(access_flags)、名称索引)(name_index)、描述符索引(descrip tor_index)、属性表集合(attributes)几项,如下所示。这些数据项目的含义也与字段表中的非常类似,仅在访问标志和属性表集合的可选项中有所区别。
1 | |
因为volatile关键字和transient 关键字不能修饰方法,所以方法表的访问标志中没有了 ACC_VOLATILE标志和ACC_TRANSIENT标志。与之相对,synchronized、native、strictfp和abstract关键字可以修饰方法,方法表的访问标志中也相应地增加了ACC_SYNCHRONIZED、 ACC_NATIVE、ACC_STRICTFP和ACC_ABSTRACT标志。
| 标 志 名 称 | 标 志 值 | 含 义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 方法是否为public |
| ACC_PRIVATE | 0x0002 | 方法是否为private |
| ACC_PROTECTED | 0x0004 | 方法是否为protected |
| ACC_STATIC | 0x0008 | 方法是否static |
| ACC_FINAL | 0x0010 | 方法是否final |
| ACC_SYNCHRONIZED | 0x0020 | 方法是否synchronized |
| ACC_BRIDGE | 0x0040 | 方法是否是由编译器产生的桥接方法 |
| ACC_VARARGS | 0x0080 | 方法是否接收不定参数 |
| ACC_NATIVE | 0x0100 | 方法是否是native方法 |
| ACC_ABSTRACT | 0x0400 | 方法是否是abstract |
| ACC_STRICT | 0x0800 | 方法是否为strictfp |
| ACC_SYNTHETIC | 0x1000 | 方法是否由编译器自动产生 |
我们主要来看下 add 方法,具体如下:

从图中我们可以看出 add 方法的以下字段的具体值:
- access_flags = 0x0001 也就是访问权限为 public。
- name_index = 0x0011 指向常量池中的第 17 个常量,也就是“add”。
- type_index = 0x0012 指向常量池中的第 18 个常量,也即是 (I)。这个方法接收 int 类型参数,并返回 int 类型参数。
属性表集合
在之前解析字段和方法的时候,在它们的具体结构中我们都能看到有一个叫作 attributes_info 的表,这就是属性表。
属性表并没有一个固定的结构,各种不同的属性只要满足以下结构即可:
1 | |
JVM 中预定义了很多属性表,这里重点讲一下 Code 属性表。
Java程序方法体里面的代码经过 Javac 编译器处理之后,最终变为字节码指令存储在Code属性内。 Code属性出现在方法表的属性集合之中,但并非所有的方法表都必须存在这个属性,譬如接口或者抽象类中的方法就不存在Code属性,如果方法表有Code属性存在,那么它的结构将如下表所示。
| 类 型 | 名 称 | 数 量 |
|---|---|---|
| u2 | attribute_name_index | 1 |
| u4 | attribute_length | 1 |
| u2 | max_stack | 1 |
| u2 | max_locals | 1 |
| u4 | code_length | 1 |
| u1 | code | code_length |
| u2 | exception_table_length | 1 |
| exception_info | exception_table | exception_table_length |
| u2 | attributes_count | 1 |
| attribute_info | attributes | attributes_count |
下面分别解释一下这些属性:
- attribute_name_index是一项指向CONSTANT_Utf8_info型常量的索引,此常量值固定为“Code”,它代表了该属性的属性名称,attribute_length指示了属性值的长度,由于属性名称索引与属性长度一共为 6个字节,所以属性值的长度固定为整个属性表长度减去6个字节。
- max_stack代表了操作数栈(Operand Stack)深度的最大值。
- max_locals代表了局部变量表所需的存储空间。
- code_length和code用来存储Java源程序编译后生成的字节码指令。
关于code_length,有一件值得注意的事情,虽然它是一个u4类型的长度值,理论上最大值可以达到2的32次幂,但是《Java虚拟机规范》中明确限制了一个方法不允许超过65535条字节码指令,即它实际只使用了u2的长度,如果超过这个限制,Javac编译器就会拒绝编译。
我们可以接着刚才解析方法表的思路继续往下分析:

可以看到,在方法类型索引之后跟着的就是“add”方法的属性。0X0001 是属性计数器,代表只有一个属性。0X000f 是属性表类型索引,通过查看常量池可以看出它是一个 Code 属性表,如下所示:
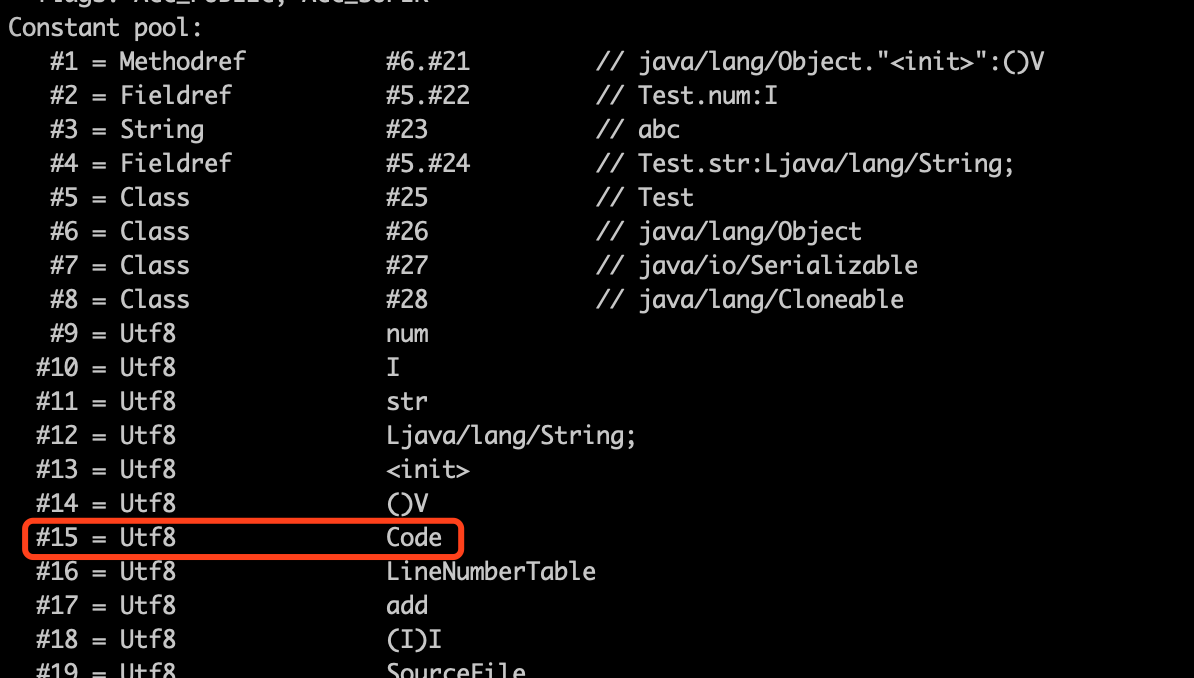
通过 javap -v Test.class 之后,可以看到方法的字节码,如下图显示的是 add 方法的字节码指令:
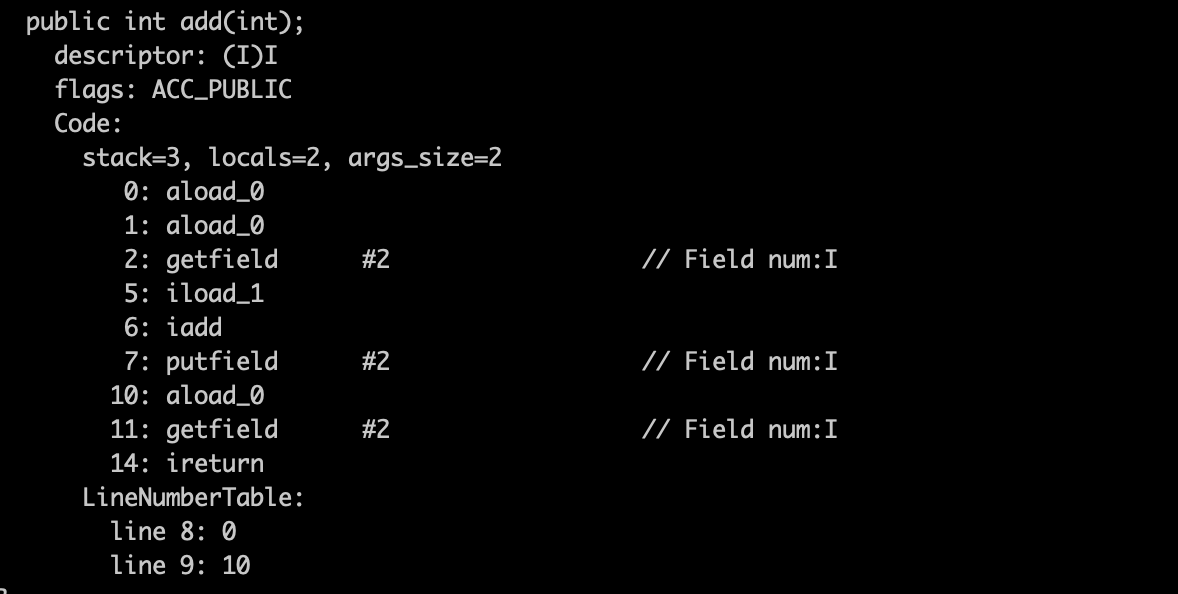
JVM 执行 add 方法时,就通过这一系列指令来做相应的操作。
参考
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!