深入理解JVM(五)——字节码基础
上篇文章中了解了虚拟机执行子系统中的栈和栈帧结构,并且学习了一些方法调用相关的字节码指令,对于方法的分派过程有了更深入的理解,接下来这篇文章来了解一下基础的字节码指令。
字节码指令
字节码指令主要有加载和存储指令、操作数栈指令、运算和类型转换指令、控制转移指令等,这一部分是了解字节码的基础。
加载和存储指令
加载(load)和存储(store)相关的指令是使用得最频繁的指令,分为load类、store类、常量加载这三种。
- load类指令:将局部变量表中的变量加载到操作数栈,比如iload_0将局部变量表中下表为0的int型变量加载到操作数栈上,类似的还有lload、fload、dload、aload,分别表示加载局部变量表中long、float、double、引用类型的变量。
- store类指令:将操作数栈栈顶的数据存储到局部变量表中,比如istore_0将操作数栈顶的元素存储到局部变量表中下表为0的位置,类似的还有lstore、fstore、dstore、astore这些指令。
- 常量加载相关的指令,常见的有const类、push类、ldc类。const、push类指令是将常数值直接加载到操作数栈顶,ldc指令是从常量池加载对应的常量到操作数栈顶。
存储指令列表如下所示。
| 指 令 名 | 描 述 |
|---|---|
| aconst_null | 将null入栈到栈顶 |
| iconst_m1 | 将int类型值-1压栈到栈顶 |
| iconst_<n> | 将int类型值n(0~5)压栈到栈顶 |
| lconst_<n> | 将long类型值n(0~1)压栈到栈顶 |
| fconst_<n> | 将float类型值n(0~2)压栈到栈顶 |
| dconst<n> | 将double类型值n(0~1)压栈到栈顶 |
| bipush | 将范围在-128~127的整型值压栈到栈顶 |
| sipush | 将范围在-32768~32767的整型值压栈到栈顶 |
| ldc | 将int、float、String类型的常量值从常量池压栈到栈顶 |
| ldc_w | 作用同ldc,不同的是ldc的操作码是一个字节,ldc_w的操作码是两个字节,即ldc只能寻址255个常量池的索引值,而ldc_w可以覆盖常量池所有的值 |
| ldc2_w | 将long或double类型的常量值从常量池压栈到栈顶 |
| <T>load | 将局部变量表中指定位置的int、long、float、double、引用类型、boolean、byte、char、short类型变量加载到栈上 |
| <T>load_<n> | 将局部变量表中下标为n(0~3)的变量加载到栈上,T可以为i、l、f、d、a |
| <T>aload | 将指定数组中特定位置的数据加载到栈上,T可以为i、l、f、d、a、b、c、s |
| <T>store | 将栈顶数据存储到局部变量表中的特定位置,T可以为i、l、f、d、a |
| <T>store_<n> | 将栈顶变量数据存储到局部变量表中下标为n(0~3)的位置,T可以为i、l、f、d、a |
| <T>astore | 将栈顶数据存储到数组的指定位置,T可以为i、l、f、d、a、b、c、s |
操作数栈指令
常见的操作数栈指令有pop、dup和swap。pop指令用于将栈顶的值出栈,dup指令用来复制栈顶的元素并压入栈顶,swap用于交换栈顶的两个元素,如下图所示。
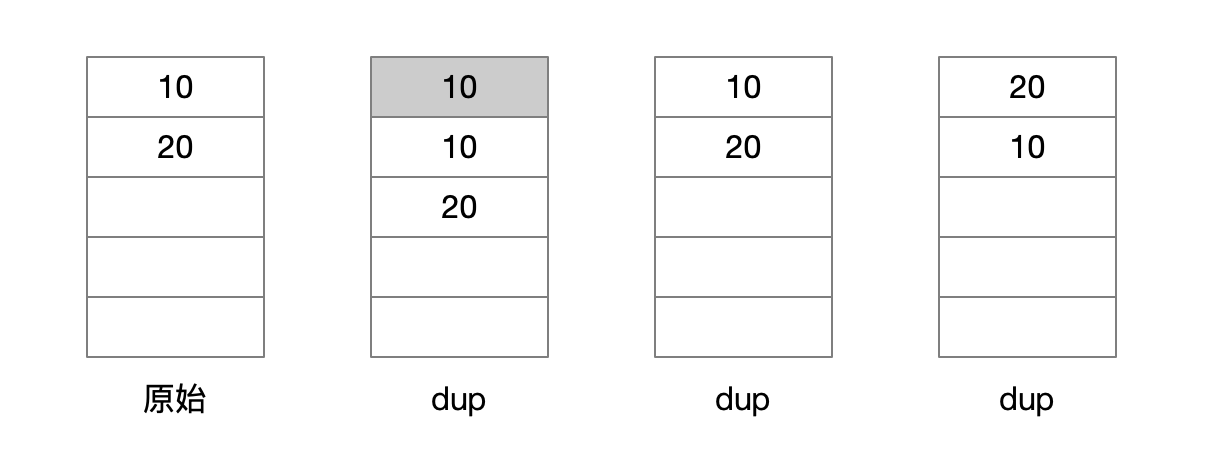
另外还有几个复杂一点的指令,如下操作数栈指令列表所示。
| 指 令 名 | 字 节 码 | 描 述 |
|---|---|---|
| pop | 0x57 | 将栈顶数据(非long和double)出栈 |
| pop2 | 0x58 | 弹出栈顶一个long或double类型的数据或者两个其他类型的数据 |
| dup | 0x59 | 复制栈顶数据并将复制的数据入栈 |
| dup_x1 | 0x5A | 复制栈顶数据并将复制的数据插入到栈顶第二个元素之下 |
| dup_x2 | 0x5B | 复制栈顶数据并将复制的数据插入到栈顶第三个元素之下 |
| dup2 | 0x5C | 复制栈顶两个数据并将复制的数据入栈 |
| dup2_x1 | 0x5D | 复制栈顶两个数据并将复制的数据插入到栈第二个元素之下 |
| dup2_x2 | 0x5E | 复制栈顶两个数据并将复制的数据插入到栈第三个元素之下 |
| swap | 0x5F | 交换栈顶两个元素 |
运算和类型转换指令
针对Java中的加减乘除相关语法,字节码也有对应的运算指令,如下表示所示。
| 运算符 | int | long | float | double |
|---|---|---|---|---|
| + | iadd | ladd | fadd | dadd |
| - | isub | lsub | fsub | dsub |
| / | idiv | ldiv | fdiv | ddiv |
| * | imul | lmul | fmul | dmul |
| % | irem | lrem | frem | drem |
| negate(-) | ineg | lneg | fneg | dneg |
| & | iand | land | – | – |
| | | ior | lor | – | – |
| ^ | ixor | lxor | – | – |
这里需要注意的是,如果需要进行运算的数据类型不一样,会涉及到类型转换(cast),例如1.0 + 1 对应的字节码为:
1 | |
这里fadd指令只支持对两个float类型的数据做相加操作,为了支持这种运算,JVM会先把int类型的数据转为float类型然后再相加,这种类型转换称为宽化类型转换(widening)。
控制转移指令
控制转移指令用于有条件和无条件的分支跳转,常见的if-then-else、三目表达式、for循环、异常处理等都属于这个范畴。对应的指令集包括:
- 条件转移:ifeq、iflt、ifle、ifne、ifgt、ifge、ifnull、ifnonnull、if_icmpeq、if_icmpne、if_icmplt、if_icmpgt、if_icmple、if_icmpge、if_acmpeq和if_acmpne。
- 复合条件转移:tableswitch、lookupswitch。
- 无条件转移:goto、goto_w、jsr、jsr_w、ret。
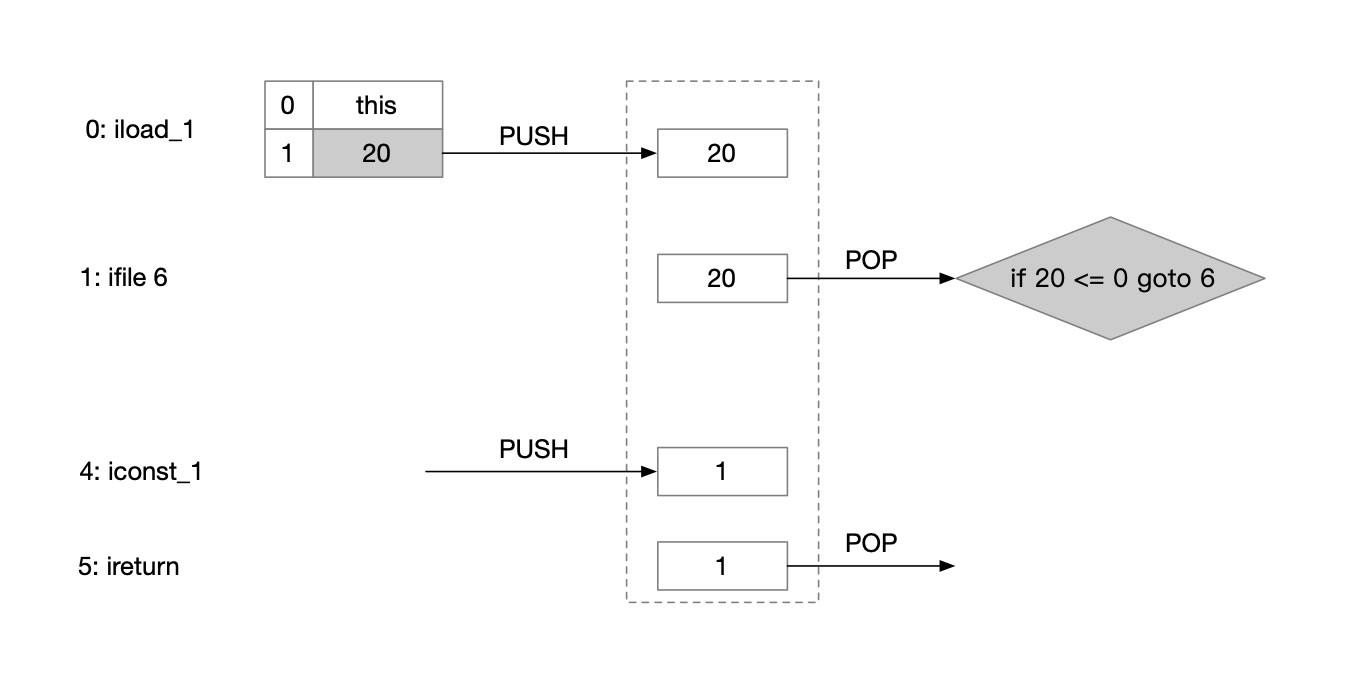
以下面代码为例来分析字节码,它的作用是判断一个整数是否为整数。
1 | |
对应的字节码如下所示。
1 | |
假设n等于20,调用isPositive(20)方法操作数栈的变化情况如下图所示。
 所所有控制转移指令如下表所示。
所所有控制转移指令如下表所示。
| 指 令 名 | 字 节 码 | 描 述 |
|---|---|---|
| ifeq | 0x99 | 如果栈顶int型变量等于0,则跳转 |
| ifne | 0x9A | 如果栈顶int型变量不等于0,则跳转 |
| iflt | 0x9B | 如果栈顶int型变量小于0,则跳转 |
| ifge | 0x9C | 如果栈顶int型变量大于等于0,则跳转 |
| ifgt | 0x9D | 如果栈顶int型变量大于0,则跳转 |
| ifle | 0x9E | 如果栈顶int型变量小于等于0,则跳转 |
| if_icmpeq | 0x9F | 比较栈顶两个int型变量,如果相等则跳转 |
| if_icmpne | 0xA0 | 比较栈顶两个int型变量,如果不相等则跳转 |
| if_icmplt | 0xA1 | 比较栈顶两个int型变量,如果小于则跳转 |
| if_icmpge | 0xA2 | 比较栈顶两个int型变量,如果大于等于则跳转 |
| if_icmpgt | 0xA3 | 比较栈顶两个int型变量,如果大于则跳转 |
| if_icmple | 0xA4 | 比较栈顶两个int型变量,如果小于等于则跳转 |
| if_acmpeq | 0xA5 | 比较栈顶两个引用类型变量,如果相等则跳转 |
| if_acmpne | 0xA6 | 比较栈顶两个引用类型变量,如果不相等则跳转 |
| goto | 0xA7 | 无条件跳转 |
| tableswitch | 0xAA | switch条件跳转,case值紧凑的情况下使用 |
| lookupswitch | 0xAB | switch条件跳转,case值稀疏的情况下使用 |
for语句的字节码原理
下面通过分析一段for循环代码来理解上述字节码指令。
纵观所有的字节码指令,并没有与for名字相关的指令,那么for循环的实现原理是怎样的呢?
以下列为例,看看JVM是如何处理高级for循环的。
1 | |
同样的,使用 javac -p 命令编译后,通过javap -c -v -l 来查看字节码:

为了方便理解,我们可以把局部变量表画出来,如下图所示。
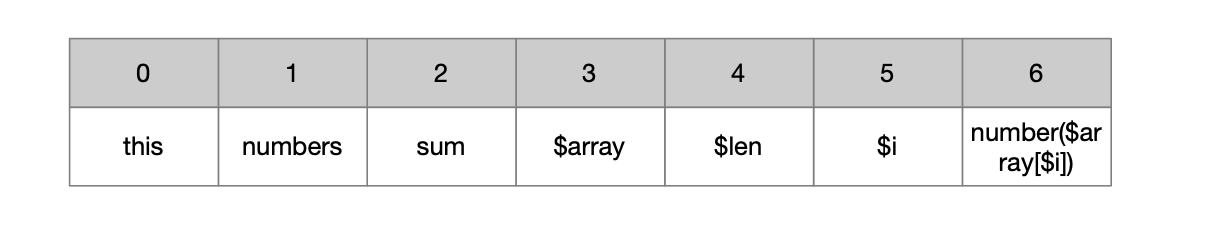
下面以执行sum(new int[]{0,20,30});为例来逐行分析字节码执行过程。
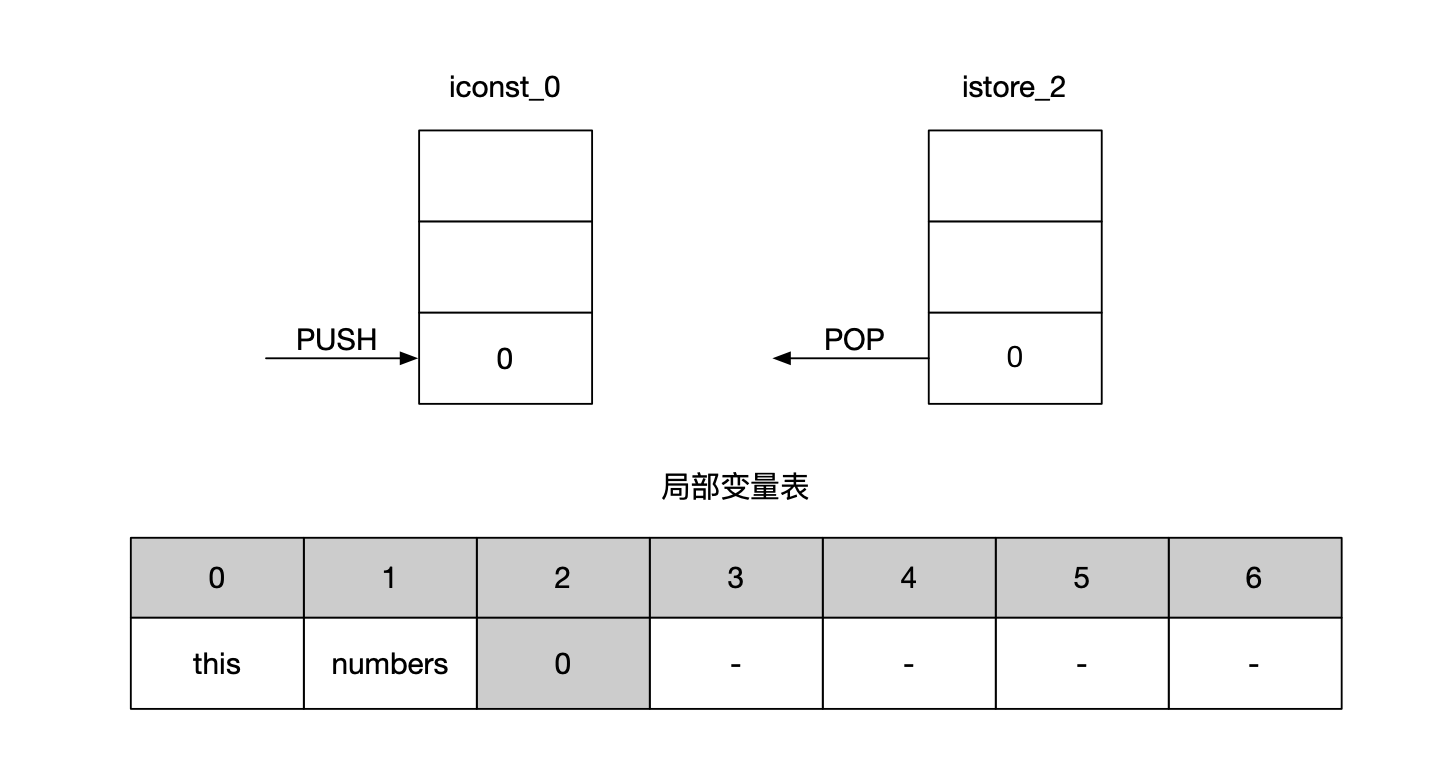
第0~1行:把常量0加载到操作数栈上,随后通过istore_2指令将0出栈赋值给局部变量表中下标为2的元素,就是将sum赋值为0。此时的局部变量表和操作数栈如下图所示。
第2~9行:初始化循环控制变量,可以使用如下伪代码表示。
1 | |
第2~3行:aload_1指令的作用是加载局部变量表中下标为1的变量(参数numbers),astore_3指令的作用是将栈顶元素存储到局部变量表下标为3的位置上,这里记为$array,如下图所示。
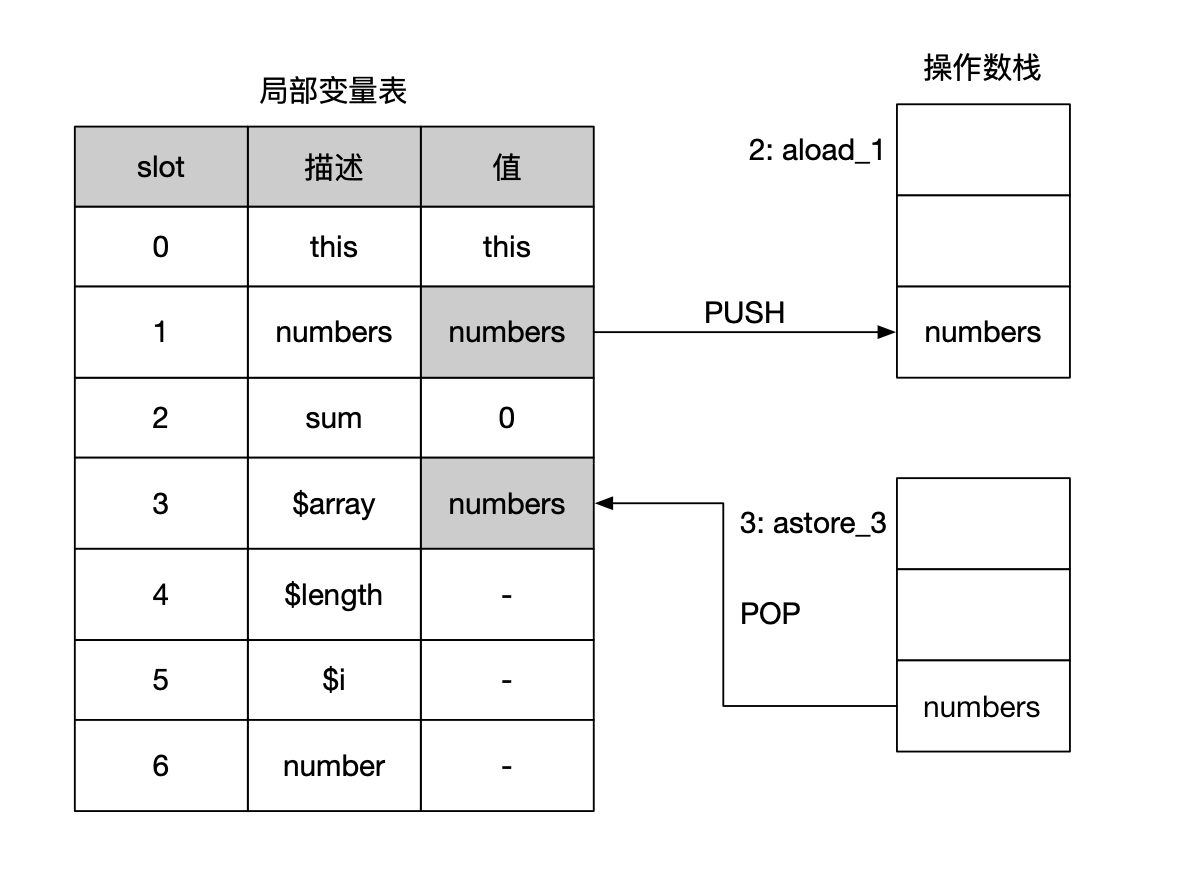
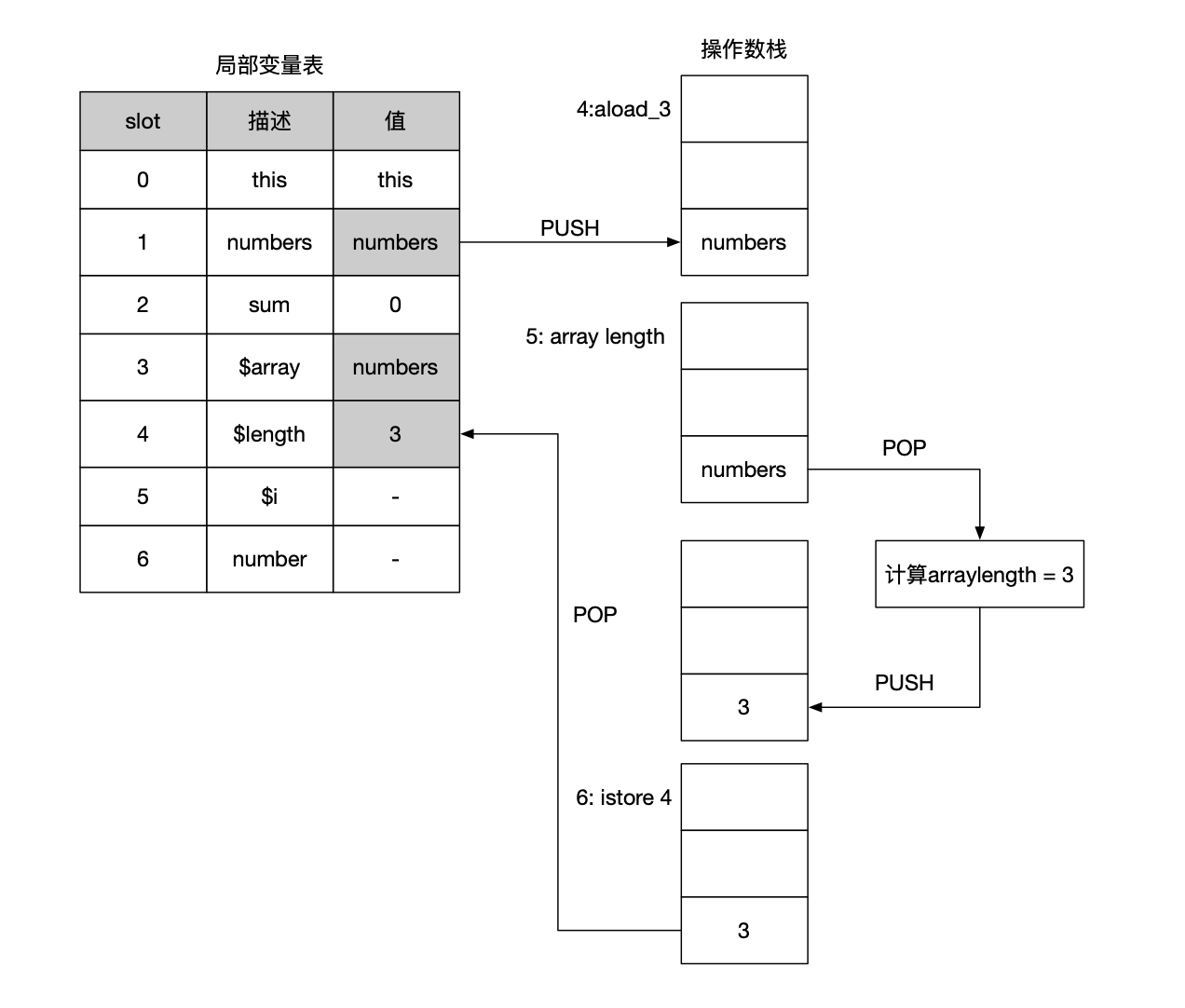
第4~6行:计算数据的长度,astore_3加载$array到栈顶,调用arrayLength指令获取数组长度存储到栈顶,随后调用istore 4将数组长度存储到局部变量表的第4个位置,这里记为$len,如下图所示。
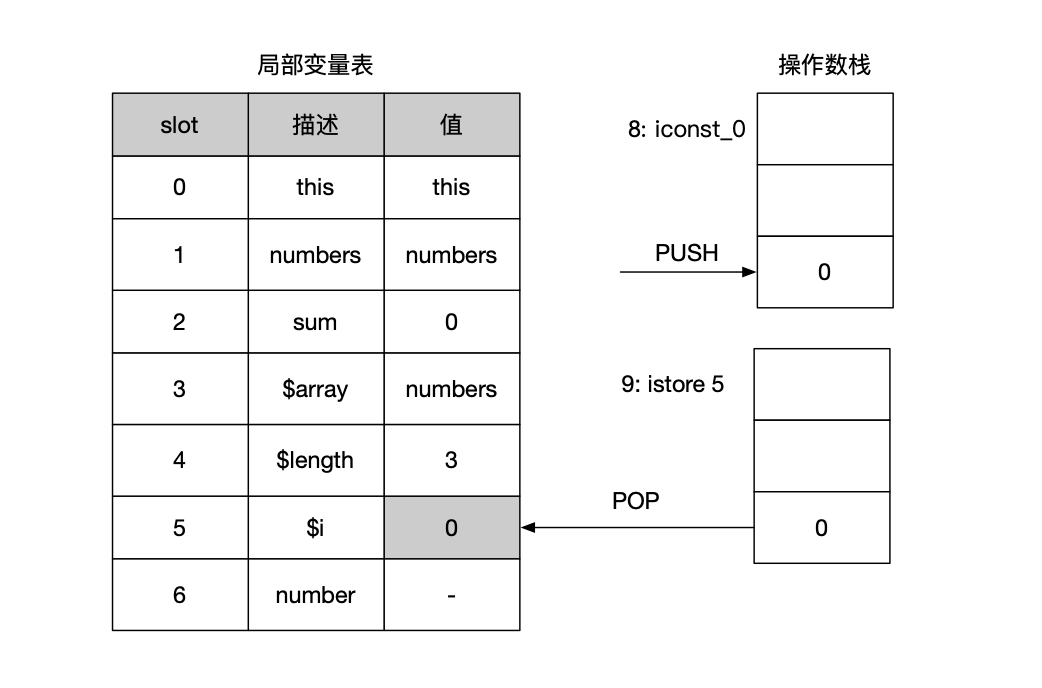
第8~9行:初始化数组遍历的下标初始值。iconst_0将0加载到操作数栈上,随后istore 5将栈顶的0存储到局部变量表中的第5个位置,这个局部变量是数据变量的下表初始值,这里记为$i,如下图所示。
第11~32行是循环体执行过程。
第11~15行的作用是判断循环能否继续:
1 | |
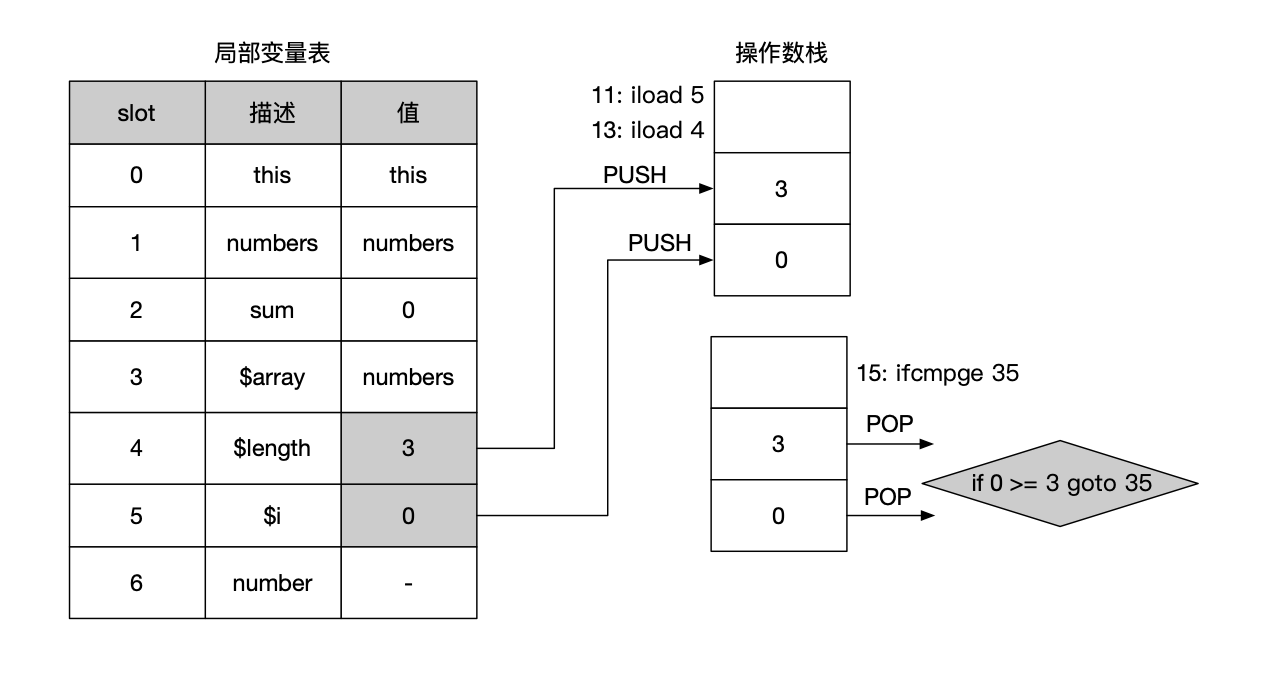
首先通过iload 5和iload 4加载局部变量表中下标5和4的变量到栈顶,参照上图中的局部变量表我们知道下标5和下标4的变量分别是数组下标$i和数组长度$len。
接着会调用if_icmpge进行条件判断,如果$i >= $len,则直接跳转到第35行指令处,for循环结束,否则继续往下执行。过程如下图所示。
第18~22行的作用是把$array[$i]赋值给number。aload_3加载$array到栈上,iload 5加载$i到栈上,然后iaload指令把下标为$i的数组元素加载到操作数栈上,随后istore 6将栈顶元素存储到局部变量表下标为6的位置上,如下图所示。
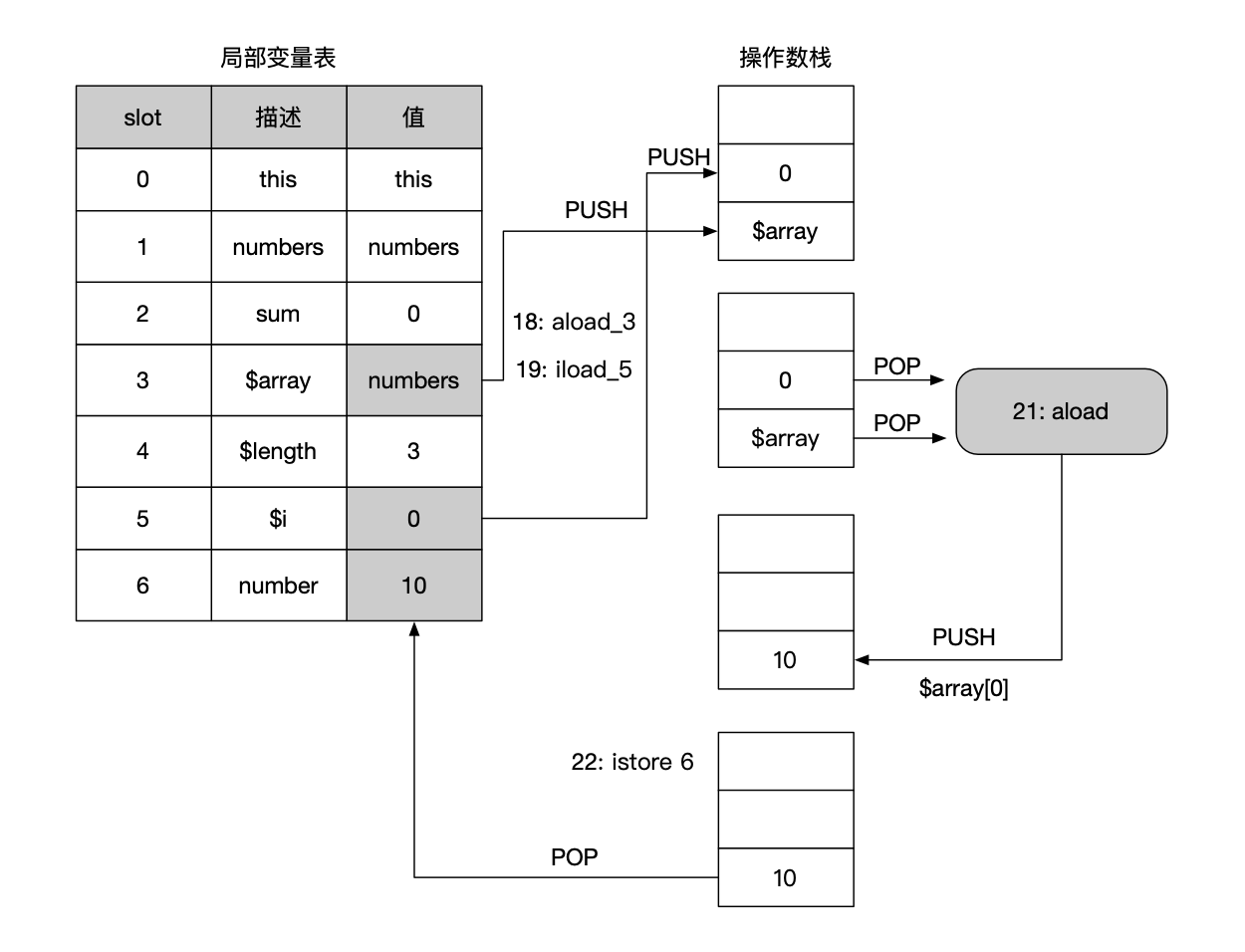
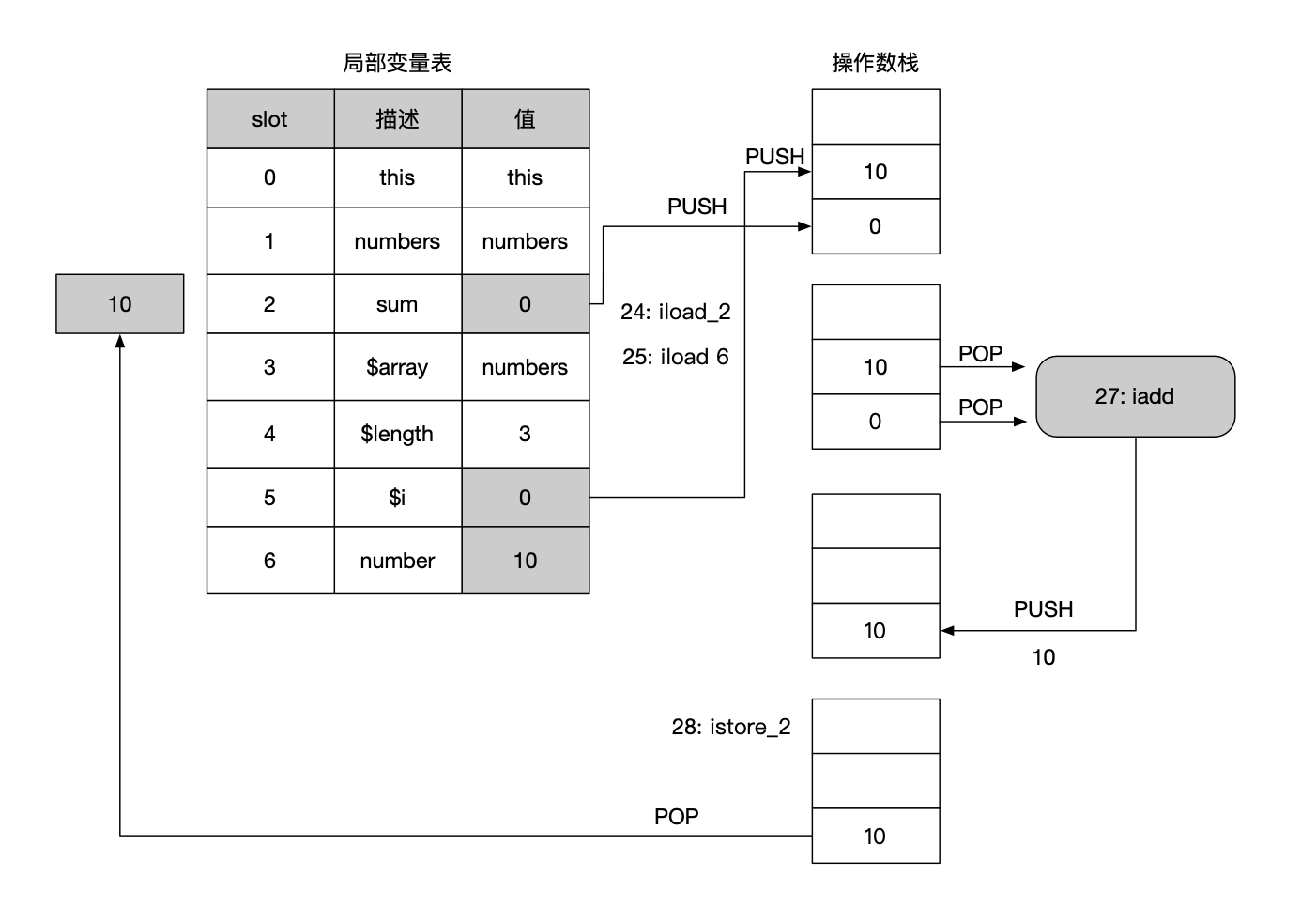
第24~28行:iload_2 和 iload 6指令把sum和number值加载到操作数栈上,然后执行iadd指令进行整数相加,如下图所示。
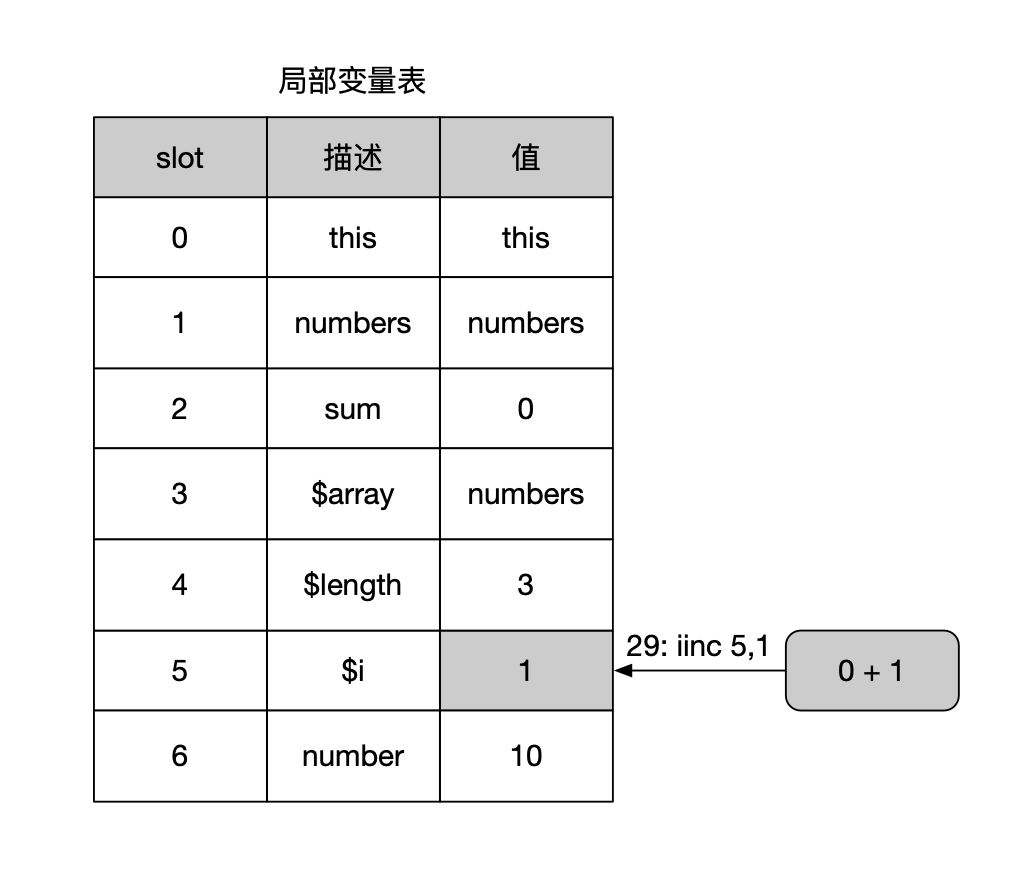
第29行:”iinc 5,1“指令对执行循环后的$i加一。iinc指令比较特殊,它并不依赖于操作数栈,而是直接对局部变量进行自增,再将结果出栈存储到局部变量表,因此效率非常高。
第32行:goto 11指令无条件跳转到第11行继续进行循环条件判断。
经过上述分析,很容易发现所谓”高级”for循环翻译成字节码后实际上与普通的for循环并无差别,只是个语法糖而已。
swtich-case底层实现原理
switch-case语法实现原理依赖于tableswitch和lookupswtich两条字节码指令。先来看下面的与其字节码:
1 | |
这里使用了tableswitch指令,之前说过tableswitch指令在case比较紧凑的情况下使用。这里需要特别注意的是,代码中并没有102和103两个case,字节码中却自动帮我们“补齐”了,实际上是编译器对“紧凑”case的优化:一是使用tableswitch;二是case出现断层时自动补齐为连续的值。这样的好处是由于case是连续的所以可以以O(1)的时间复杂度来进行查找。
再看一个case比较“稀疏”的情况:
1 | |
可以看到这种情况case将不会被补齐,而且没有使用tableswitch而是lookupswitch字节码指令,并且case会经过排序,使得lookupswitch可以以二分查找的方式进行case的查找,时间复杂度为O(log n)。
String的switch-case实现的字节码原理
上面讨论的两种情况都是基于case是整形数值的情况,Java中支持在Swtich中使用String,那么这是如何实现的呢?
同样以一段代码为例:
1 | |
对应字节码如下图:
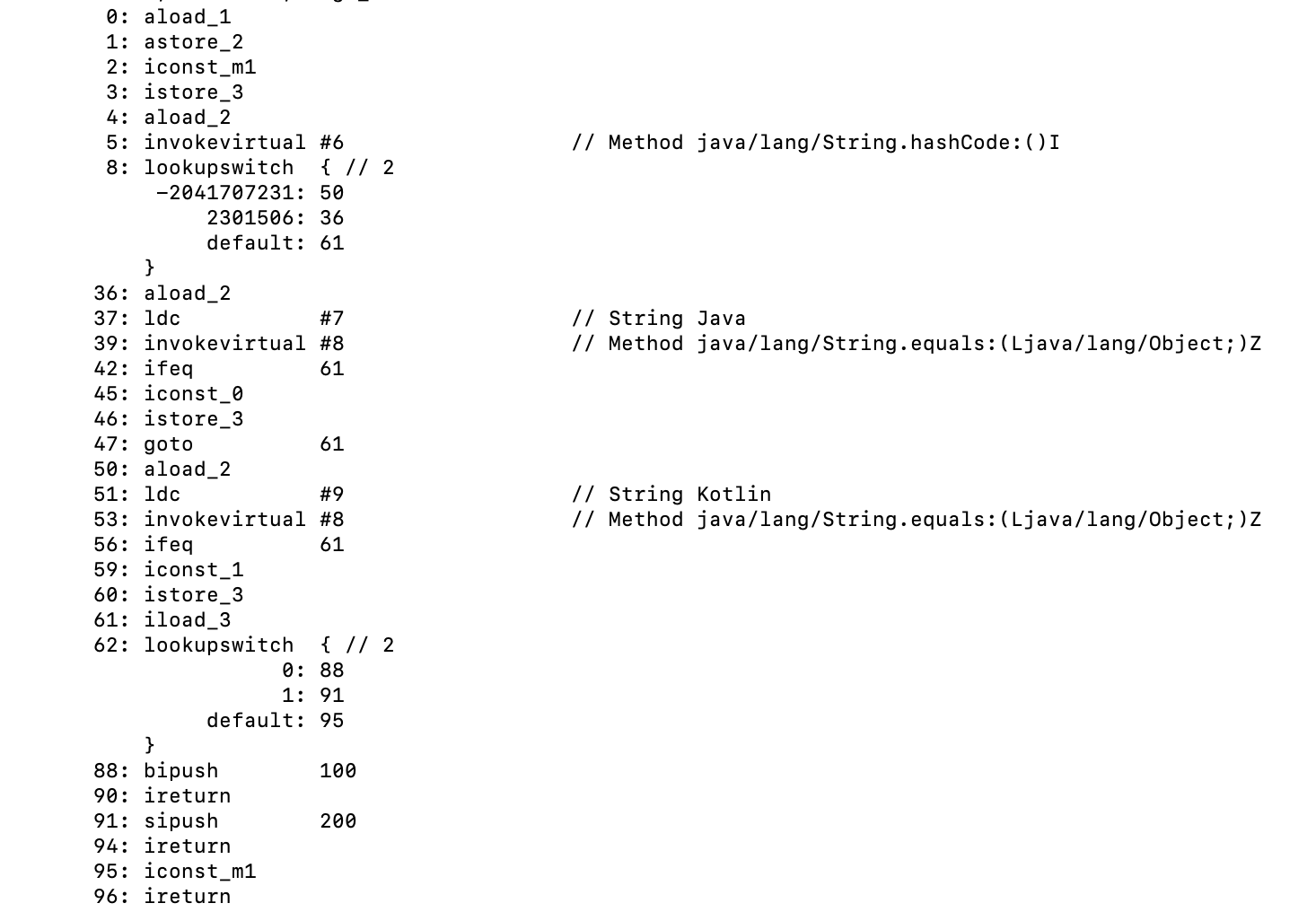
这里有几个比较关键的点,第5行中调用了String#hashCode()方法,并且选择使用lookupswitch指令,判断case后跳转到对应的行数。
由于hash值相同的String也有可能是不同字符串,因此随后会调用String#equals()方法来判断是否是相等。这里使用了ifeq指令,ifeq用于判断栈顶数据是否等于0,是则跳转到对应的行数,相当于等于false时跳转。如果相等将会继续执行,使用iconst_0将常量0压入栈顶,表示匹配了case0,或者使用iconst_1将常量1压入栈顶,表示匹配了case1,随后使用istore_3存入局部变量表。
接着就是第61~96行的处理了。61行拿到刚刚存入的0或者1,通过lookupswitch来判断跳转到不同的字节码行数执行case里面的操作。
++i和i++的字节码源码
在日常开发中我们通常不会使用++i和i++这两种容易让人困惑的自增方式,而使用更加清晰的i = i + 1,不过它们很容易在面试中作为陷阱题出现,例如下列代码:
1 | |
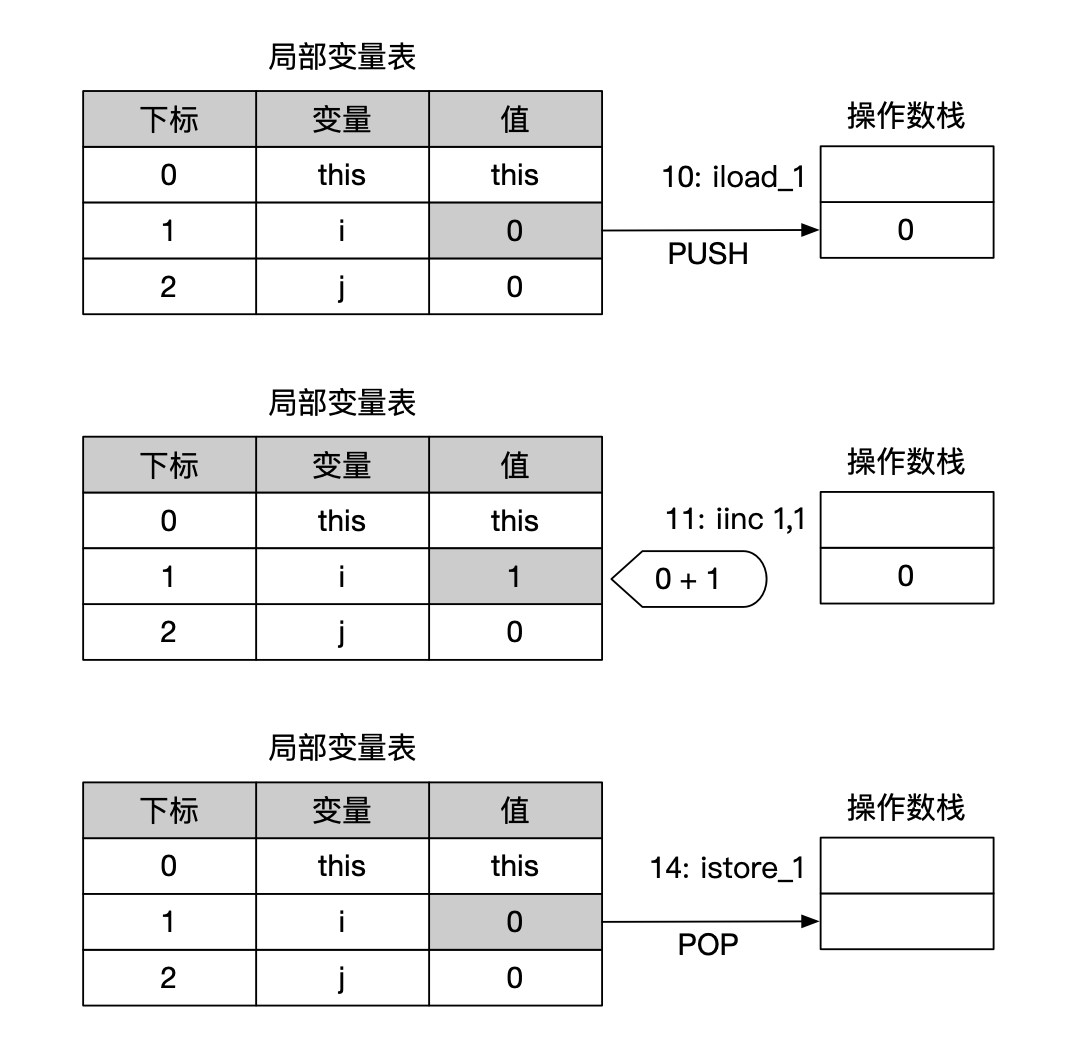
这段代码的输出结果是什么呢?答案是0,查看 i = i++ 的字节码如下:
1 | |
第10行:iload_1把局部变量表slot = 1的变量(i)加载到操作数栈上。
第11行:“iinc 1,1”对局部变量表slot = 1的变量(i)直接加1,但是这时候栈顶的元素没有变化,还是0.
第14行:istore_1 将栈顶元素出栈赋值给局部变量表slot = 1的变量,也就是i。此时,局部变量i又被赋值为0,前面的iinc指令对i的加一操作被覆盖。
整个过程局部变量表和操作数栈的变化如下图所示。
如果把上面代码的i = i++替换成 i = ++i,则可以正常输出打印50。替换后的字节码如下:
1 | |
与上面i++的字节码不同的是,这里先对局部变量表中第1位变量进行了加一,然后将其加载到操作数栈,随后重新存储到局部变量表中。
对象相关的字节码指令
1.<init>方法
<init>方法是对象初始化方法,类的构造方法、非静态变量的初始化、对象初始化代码块都会被编译进这个方法中。例如下面的代码:
1 | |
对应字节码为:
1 | |
Initializer()方法对应<init>对象初始化方法,其中57行将成员变量a赋值为10,1012行将b赋值为10,13~15行将c赋值为30。可以看到,虽然我们将变量a和变量b分别放在构造方法外和构造代码块中初始化,实际上也会统一编译到<init>方法里面。
2.new、dup、invokespecial对象创建三条指令
Java 中通过 new 关键字来创建对象,字节码中也有一个叫 new 的指令,但两者不是一回事。以下面的代码为例:
1 | |
编译后对应字节码:
1 | |
出去第 7 行的存储指令,new 关键字经过编译后实际上生成了 new-dup-invokespecial 3行字节码。new指令很容易理解,invokespecial 则是用于调用对象<init>方法来初始化对象,那么中间这个dup指令的作用是什么呢?
dup指令的含义是复制栈顶的数据并且插入到栈顶,在第0行时通过new指令创建了Initializer的一个实例然后加入到栈顶,接着如果直接通过invokespecial调用其构造方法,由于invokespecial会消耗栈顶的类实例引用,会导致操作数栈为空,使得刚刚创建的对象丢失。因此在invokespecial调用前需使用dup复制一份实例,随后就可以通过astore_1指令将其存入局部变量表了。
3.<clinit>方法
<clinit>是类的静态初始化方法,同样的,类静态初始化代码块、静态变量初始化都会被编译进这个方法中。javap输出字节码中的 static{} 表示<cinit>方法。
参考
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!